He leaves the defaults alone and ends up with a network that looks like this:
Dennis starts creating EC2 instances and notices that they are instantiated into a particular subnet, so Dennis drops his web server into his Public subnet and his database server into Private. Dennis slaps an Elastic IP onto his web server, creates some DNS entries in Route 53 and is off to the AWS races.
Now Dennis's VPC looks like this:
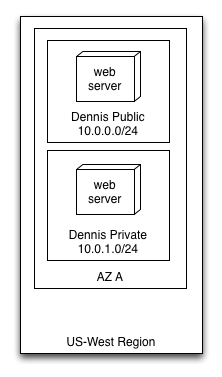
Dennis shows his manager his handiwork and explains the cost of running on AWS rather than recapitalizing the old hardware servers that are due. Dennis's boss takes a look at the numbers and tells Dennis to port ten more applications to AWS ASAP.
Dennis walks the halls and talks to the leads on each project to collect requirements, beginning with his friend Jean.
Jean tells him that there's no way she'll share subnets with Dennis's application, so he'll need new subnets with different routing rules and ACLs to keep Dennis's application from accessing his servers.
Dennis presents the following architecture to Jean:
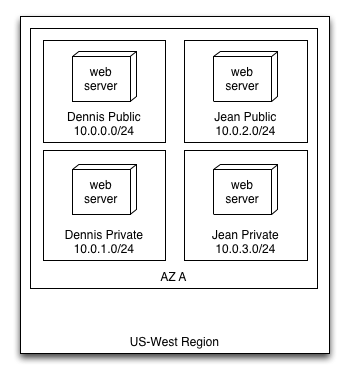
Jean signs off on this architecture and some more Route53 records are created and the application is launched publicly in AWS. Dennis repeats this process eight more times, and each system owner asks for the now "standard" architecture that Jean defined. We now have:
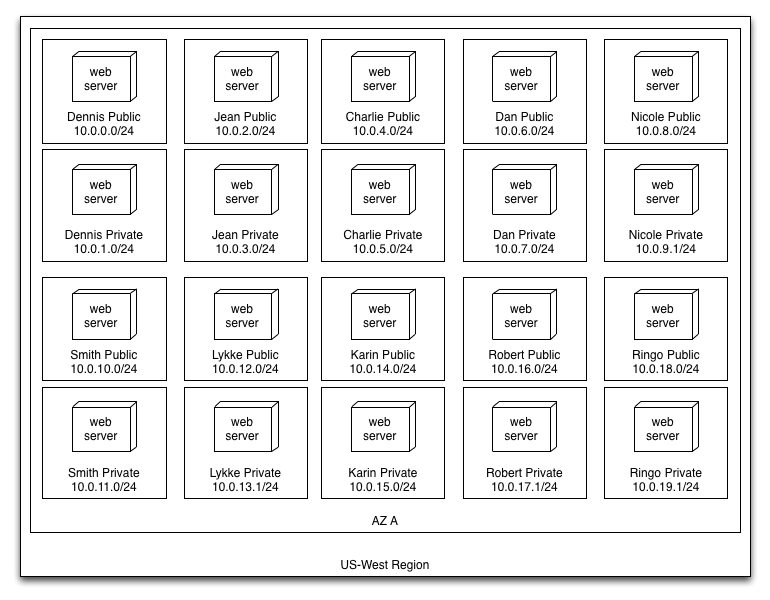
It takes Dennis and the teams about a week to build out this new set of resources on AWS and get their applications running. At the next management meeting, Jean presents her results showing huge savings in hardware and O&M. The next day Dennis receives 20 emails on moving some of Complicado's larger business systems to AWS. Dennis starts porting over the next three months until he has used 70% of the address space in his /16 VPC and instantiated 632 EC2 instances across all the applications. All of the public DNS records for Complicado's web applications are now pointed to this VPC and they are handling 50,000 users/day on their shiny new AWS infrastructure and saving a ton of money.
There are two fatal flaws to this ugly VPC.
Too Many Subnets
Underutilization of IP address space means the company will run out of subnets to allocate long before they've used anything close to the available addresses. Handing out /24 subnets in order to create segmentation for security means most applications are wasting the majority of their assigned addresses. Breaking up the /16 into more, smaller subnets will generally create some waste or impose artificial and arbitrary limits to server counts for the more distributed applications.
Subnetting is a form of provisioning, and provisioning is an evil. It is sometimes a necessary evil, but it always implies predicting the future which is rarely if ever accurate. With cloud computing, you only want to use what you need and when you need it. In the VPC scenario this means limiting your subnetting by sharing subnets and using other security mechanisms (or completely automating your network architecture, but for most organizations that is a rather difficult challenge.)
You may be thinking "but I can just make another VPC and start filling that one up". You can, but you will pay "data out" costs for every byte that traverses the VPC/VPC boundary because it is Internet traffic. In theory you may also be sending all those bytes across public Internet (though this is fairly unlikely at any moment in time).
What you really want to do is use Security Groups properly to isolate your applications and have them share subnets. In part 3 of this post, I'll show you the effective use of SGs. More subnets rarely provides better security and it always reduces efficiency and resiliency.
Not Enough AZs
Complicado has used over half their subnets in one AZ. When they decide to make their applications highly available by spreading them across AZs, they will have a mismatch due to 70% of the /16 already being committed to one AZ. When this happens, it nearly always means building a new VPC and moving all the instances over. That means spending on double the instances for a period of time, spending on building out the new environment, and finally outages as the applications are moved over.
This design has tried to sacrifice its efficiency and resiliency for security, but in fact isn't any more secure than some other designs that do offer high resiliency and efficiency. One of those designs will be explored in part 3.
