Not surprisingly, cloud service providers offer familiar topologies of services for folks conversant with the data center: virtual machines and containers, virtual networks, load balancers, etc. But, these really are metaphors rather than the traditional things they resemble on data floors. They are useful abstractions in composing applications with semi-traditional architectures. The metaphors nevertheless are imperfect. Compared with their on-premise equivalents, the cloud forms of these services have different behaviors, semantics, and best practices associated with them. However, those cloud forms are relatively easy to wrap your mind around if you’re already familiar with the concepts.
We're in a transitional period with cloud computing, where metaphors are needed to conceptualize what is offered. This period doesn't represent an end-state by any means. It’s likely that we are still in an invention phase of the cloud and will be for several more years at least. Ultimately, perhaps the cloud is better imagined as our first, planet-scale distributed computer. Services like AWS Lambda arguably are starting to demonstrate this idea.
Lambda and Serverless Infrastructure
If you’re unfamiliar with Lambda, it’s what has been termed a "serverless" computing service from AWS, which uses events to drive resource allocation and computation. Lambda is named after functions from lambda calculus and programming. Those functions act as a good analogy for the service. In Lambda, you write a function and connect it to other services, such as API Gateway, S3, Kinesis, EC2, etc., in order to compose part of an application. These functions must be internally stateless. They are billed on a 100ms basis, meaning you only pay for what you really use, which is the principal economic benefit of utility/cloud computing. Lambda also scales to whatever is needed for your service, making architecting for scale significantly easier than with provisioned compute instances or containers.
You may be wondering whether Lambda is similar to Heroku or even Google Application Engine. Not really. There are some key differences that make it unlike a PaaS service. Lambda is an opinionated service regarding application architecture in a way that traditional PaaS offerings aren't. It doesn't pretend to be a traditional computer or cluster of traditional computers. Instead, Lambda is event-driven by nature and imposes statelessness at the function level. This means you'll need to think a little differently about how to compose an application. You gain near infinite scalability and very low cost compared to compute instances or containers. As a trade-off, you commit time to learning, but may very well invent some new patterns during your experimentation and inquiry.
Let’s first dig into the fact that Lambda is event-driven. This means thinking of your application as a collection of functions that are triggered by events, either from users of the system or from changes to state in the system. Events from users are easy to relate to—a user performs an action and an event is fired. Events from changes to system state are something like a database trigger, in that changes to the persistence services fire events for functions that are registered to them. This event-driven style of architecture effectively allows for infinite scaling when coupled with stateless functions.
Second, Lambda is stateless in that no data is preserved on the instance once the function is run. As state isn't maintained in the Lambda functions, other services such as DynamoDB are used in a Lambda application. This divides the application architecture between state and computation. In the past, we have tended to mix these more liberally and have separated concerns more around business functions. If you're used to object-oriented programming, this merger of data and logic is the central compositional pattern in most cases, so designing and programming with Lambda might feel pretty alien. But keep in mind the huge benefits.
Microservice or Lambda Patterns?
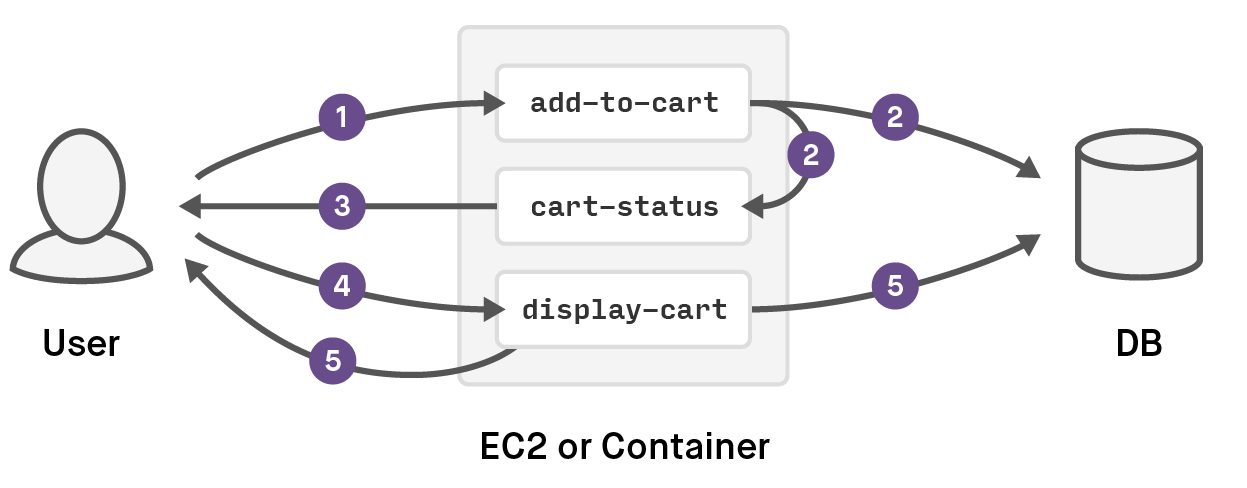
While this post isn't a tutorial, it might be useful to describe how a traditional set of functions in a web application could map to Lambda at a high level. Imagine that you have a shopping cart on your web application. In a microservice web app, you might have an add-to-cart operation running on the same machine as the cart-status and display-cart operations. When a user adds an item to the cart, the add-to-cart operation is called, which puts a record into the database. The cart-status operation is then called to show that the cart now has an item in it. If the cart is clicked on, the display-cart operation is called to show the contents. The data flow is within the EC2 instance or container that has the shopping-cart service, in-memory in this simplified example shown here:
With Lambda, the three operations are written as Lambda functions, with a slightly different data flow. API Gateway is used to route the user interactions with the system to the appropriate Lambda functions, so when a user adds an item to the cart, API Gateway routes that request to the add-to-cart Lambda function, which writes a record into a DynamoDB table. The cart-status function is notified of the change to DynamoDB with an event, and the UI responds with a change showing there are items in the cart. When the cart is clicked, the API Gateway routes a request to the display-cart Lambda function. The Lambda data flow is illustrated here:
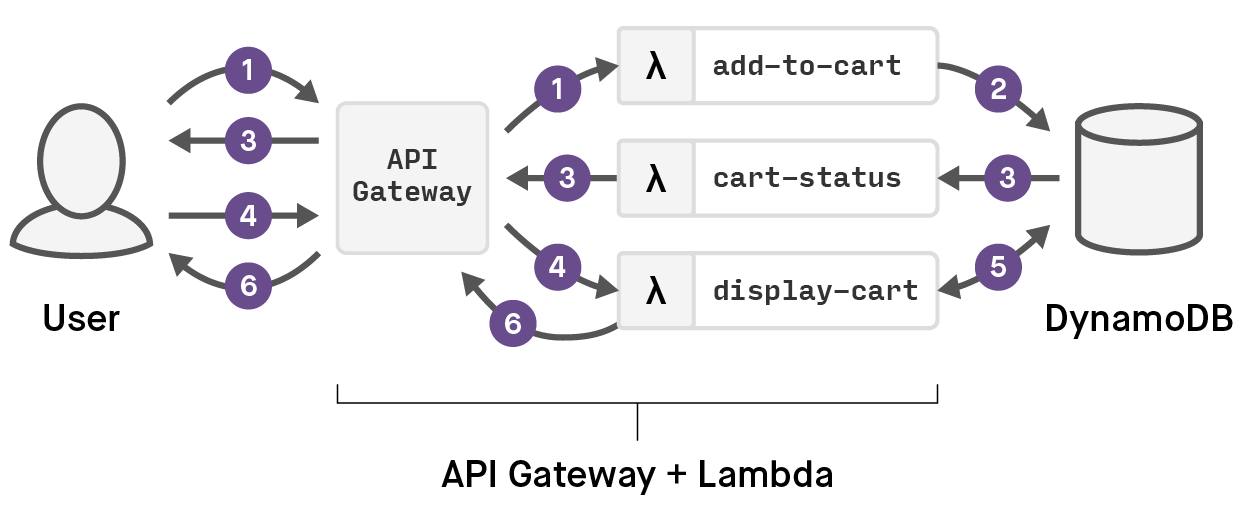
In the microservice app version, all three operations are scaled based on the overall load across them, and state is transferred in-memory, creating complication around caching and/or routing sessions to instances in order to maintain state. In the Lambda version, each function scales individually and as-needed. All state is in DynamoDB so there is no cluster coordination of any sort, at the cost of a small increase in latency.
While this is a trivial and oversimplified example, the key benefits (mentioned briefly above) to the Lambda approach are quite profound as the application scales. Remember, you are only paying for actual requests. Instantiating an EC2 instance or a container is actually pre-provisioning, which pushes the need to predict load onto you and off of AWS. At low scales, this means you can put up a system on Lambda for a trivial amount of money, but the benefits really accrue at higher scales. With microservices on compute instances with or without containers, you are making choices regarding how to combine or separate services for scaling. As your app grows, you'll almost certainly discover that you were wrong in some way in terms of separating the concerns for scaling purposes or on which metrics to scale. So, you'll be discovering where you were wrong via bad user experience or wasted resources and you’ll end up correcting via refactoring. With Lambda, each function scales independently, which puts the burden on AWS to scale the functions. You needn't concern yourself with it. The cost is in both doing things differently and spreading your application across many functions and events. That can be hard to model and manage without a system like Fugue to organize and operate the application as a whole.
When designing Fugue, we spent a lot of time reviewing and studying the history of operating systems and hardware architectures—their intricacies and their interrelationships. Lambda is the first service offering to really illustrate that the cloud is a global, general-purpose computer with a particular architecture. EC2 will be around for a long time, but services like Lambda show the potential of the cloud, especially when combined with an OS above them like Fugue. It's going to be an interesting year or ten.
