We love clouds like Amazon Web Services (AWS) and Microsoft Azure for more reasons than we can count. Because the cloud is 100% software, we can program it to respond to our application requirements automatically. Developers can innovate really fast, spinning resources up and down on demand, and we only pay for what we use.
But constant change brings risk of misconfiguration vulnerabilities that can result in compliance violations, security incidents, or data breaches. In other words, we want our developers to move fast and break things, just as long as they don’t break the really important things like our cloud security.
That’s where Cloud Security Posture Management (CSPM) comes to play to help ensure that cloud environments are configured security and in accordance with various compliance policies.

At the heart of CSPM is the detection of cloud misconfiguration vulnerabilities that can lead to compliance violations and data breaches—and do so as fast as possible before the bad guys can find and exploit them using their own automation tools. Even if you follow best practices in configuring your cloud resources securely upon provisioning, drift is inevitable. Drift is change to your cloud resources that occurs outside of your normal approval processes and deployment pipelines.
This post is about why you need automated remediation for security-critical resources to address drift and misconfiguration. Not all cloud services have the same security profile or carry the same level of misconfiguration risk. While there are likely a number of different security-critical cloud resources in your environment for which misconfiguration presents serious risk, it’s generally a good rule to start with your network (AWS VPC) and firewalls (AWS Security Groups) when implementing automated remediation. So let’s focus there.
The Risk of AWS Security Group Vulnerabilities
AWS Security Groups are the cloud’s answer to firewalls and allows you to control a resource’s inbound and outbound traffic. Security Groups can undergo a considerable amount of change. The reason is simple: manually adding Security Group rules is the easiest and fastest way to grant oneself access to a resource in order to perform a task, such as maintenance on an instance. Ask anyone managing cloud infrastructure at scale how often they see Security Group rule drift, and the answer is likely “all of the time!”
Some examples of Security Group drift that can lead to serious security incidents include:
- Open ports for 0.0.0.0/0. This is a common Security Group drift event that opens up access to the Internet. It’s typically caused when someone on your team opens up this rule so they can perform a task, such as troubleshooting and instance or obtaining logs, and then often forget to delete the rule once finished.
- Someone opens port 22, 3389, or a database port to perform maintenance on an instance, leaving behind an open door for hackers to discover.
- A Security Group is modified by closing an open port, but that port is relied upon by another user of the same Security Group, taking down the application.
The Risk of AWS VPC and Subnet Vulnerabilities
Amazon virtual private clouds (VPCs) are dedicated virtual networks for your AWS accounts that are logically isolated from other VPCs on AWS. A VPC can include one or more subnets in each Availability Zone on AWS.
Some examples of VPC and subnet drift that can lead to serious security incidents include:
- A change to route tables or a network access control list (NACL) that leaves a network exposed to unauthorized traffic.
- Lost or modified tags that render the VPC hidden to management and security tools that track cloud resources using tags.
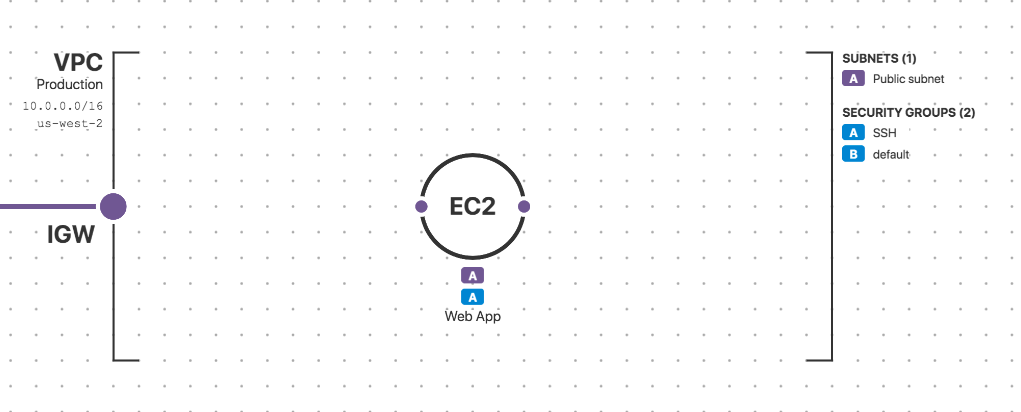
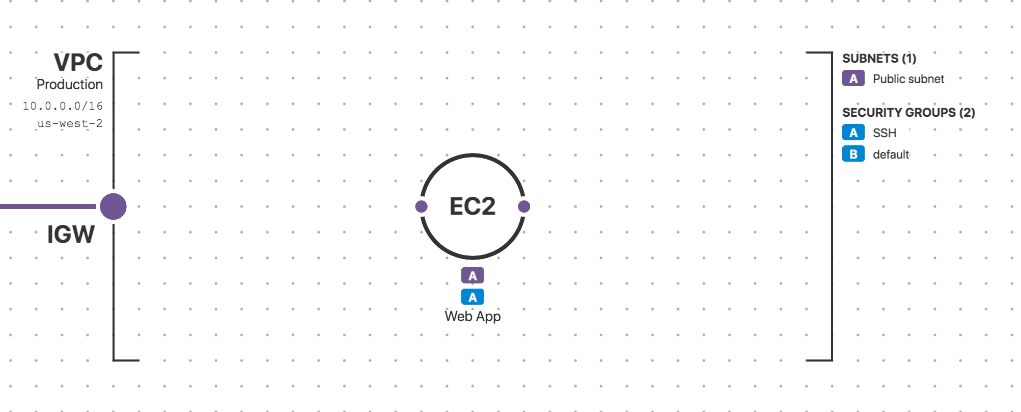 An EC2 instance inside a VPC with associated Security Groups and Subnets, as shown in Fugue's visualizer.
An EC2 instance inside a VPC with associated Security Groups and Subnets, as shown in Fugue's visualizer.
Automated Remediation is Mandatory for VPCs and Security Groups
Any action you take in the cloud can be accomplished via APIs—such as provisioning, updating, monitoring, and discovering cloud resources. This means everything is programmable and can be automated. But one area where automation has been slow to catch on is security, often due to a historic lack of trust in security automation.
But this is starting to change as teams and organizations are realizing the risks involved and the scale and complexity of manually managing cloud security at scale. Here are some of the primary drivers behind automated remediation:
- Bad actors have automation, and they’re faster than you. Take a look at the small handful of misconfiguration examples listed earlier. Hackers use tools that scan the internet looking for these, and others, in order to identify opportunities to exploit. It takes mere minutes for these tools to find your misconfiguration and swing into action and exploit your data. No human can outrun automation. Evaluate your effectiveness against drift and misconfiguration by measuring your Mean Time to Remediation (MTTR) for security-critical resources.
- To err is human, therefore humans shouldn’t be remediating misconfiguration. If your cloud misconfiguration response plan involves humans looking at screens full of alerts, prioritizing which misconfiguration events are critical, and then remediating them, you risk human error in miscategorizing them and again when remediating them.
- The cloud at scale is too vast and complex for humans to keep secure. Modern cloud environments can involve thousands of resources that span multiple regions and availability zones. Multiply that by the number of possible configuration attributes, and it’s effectively infinite. Even if you have an army of cloud security experts pointed at remediating misconfiguration, you’ll still be too slow and too error prone to sleep well at night.
Considerations When Implementing Automated Remediation
- Understand and evaluate your automated remediation options. Does the solution require you to code and maintain automation scripts (or bots), and how many scripts will you need to deploy? How many lines of code? Does the solution cover all of your security-critical resources and configuration attributes? Does it prevent the risk of destructive change that can take down your application? These are just some questions you should ask. You’ll likely have more to add based on your environment, team, and use case.
- Implement guardrails to prevent misconfiguration. Even if you’ve fully automated the remediation of cloud misconfiguration in your production environment, you still need guardrails to prevent your team from inadvertently introducing common cloud resource misconfigurations via your approved channel (e.g. CI/CD; provisioning tools). Getting your cloud environment right up front is a no-brainer.
- Give developers tools to help them “Shift Left’ on cloud security and compliance. Developers want to do the right thing and avoid introducing security vulnerabilities, but we can’t expect them to memorize a binder of compliance and security policies the size of War and Peace. With policy-as-code tools, developers can find and fix problems early in the software development lifecycle, when they’re easier and cheaper to fix. By empowering developers with security and compliance tools that work the way they work and can integrate with their toolchains, you can help avoid misconfiguration issues without slowing down innovation.
Getting Started
No team should set out to implement automated remediation for their entire cloud infrastructure environment. And it may not be necessary to do so for every single VPC and Security Group. Here’s how to know where to focus:
- Identify the cloud resources in which sensitive data resides (such as AWS RDS or DynamoDB), and then identify the VPCs and Security Groups associated with those resources. These are your ideal first candidate resources for automated remediation.
- Assess the current security posture of those resources. If you’re operating under a Compliance frameworks like SOC2, PCI, and HIPAA all include controls for how VPCs and Security Groups should be configured. If none apply, use the AWS CIS Foundations Benchmark. Make any necessary changes to address any policy violations.
- Implement your automated remediation solution for these resources. But before you deploy your solution in production, test it first! Deploy your solution to a test or staging environment that resembles production, and manually introduce misconfigurations to test how your solution handles the event, including whether or not it breaks the application. Once it’s passed your tests, then deploy to production.
One you’ve successfully implemented automated remediation for your security-critical VPCs and Security Groups, you’re ready to expand its use to your other security-critical resources.
While You’re Here…
If you’re operating at scale in the cloud and care about the security and compliance of your cloud infrastructure environments, Fugue can help. With Fugue, you can:
- Validate compliance for your cloud environments against a number of policy frameworks like CIS, HIPAA, PCI, SOC 2, NIST 800-53, ISO 27001, and GDPR.
- Get complete visibility into your cloud environments and configurations with cloud infrastructure baselining and drift detection.
- Protect against cloud infrastructure misconfiguration, security incidents, and compliance violations with self-healing infrastructure.
- Shift Left on cloud infrastructure security and compliance with CI/CD integration to help your developers move fast and safely.
- Get continuous compliance visibility and reporting across your entire enterprise cloud footprint.
Schedule a free half-hour cloud security workshop or compliance audit to get a handle on your cloud security posture.
