Back in 2006, Jeff Bezos was building Amazon Web Services (AWS) to solve a core problem for businesses: undifferentiated heavy lifting. Getting great ideas and applications to market fast is key in holding a competitive edge. If you transform parts of the IT pipeline that require a lot of time, effort, and money—the same parts that every business has to contend with—into fast, easy-to-use, efficient parts, you win. Or, at least, you’re a few laps ahead. Bezos, with foresight to grow AWS into what’s now the largest cloud provider on Earth, put it like this:
The reality, of course, today is that if you come up with a great idea you don't get to go quickly to a successful product. There's a lot of undifferentiated heavy lifting that stands between your idea and that success. The kinds of things that I'm talking about when I say undifferentiated heavy lifting are things like these: figuring out which servers to buy, how many of them to buy, what time line to buy them.
Eventually you end up with heterogeneous hardware and you have to match that. You have to think about backup scenarios if you lose your data center or lose connectivity to a data center. Eventually you have to move facilities. There's negotiations to be done. It's a very complex set of activities that really is a big driver of ultimate success.
But they are undifferentiated from, it's not the heart of, your idea. We call this muck. And it gets worse because what really happens is you don't have to do this one time. You have to drive this loop. After you get your first version of your idea out into the marketplace, you've done all that undifferentiated heavy lifting, you find out that you have to cycle back. Change your idea. The winners are the ones that can cycle this loop the fastest.
On every cycle of this loop you have this undifferentiated heavy lifting, or muck, that you have to contend with. I believe that for most companies, and it's certainly true at Amazon, that 70% of your time, energy, and dollars go into the undifferentiated heavy lifting and only 30% of your energy, time, and dollars gets to go into the core kernel of your idea.
I think what people are excited about is that they're going to get a chance they see a future where they may be able to invert those two. Where they may be able to spend 70% of their time, energy and dollars on the differentiated part of what they're doing.
AWS struck at the heart of the problem with its utility payment model for cloud, which yields even more customer value because of the efficient, abundant scaling properties that come with it. Both Capex and Opex models have transformed. Other cloud providers have followed Amazon’s lead. But, as happens in every innovative industry, cloud has presented new challenges. As cloud services and tools have proliferated like wildfire, one form of undifferentiated heavy lifting has been replaced by another. And, the new form has permeated every part of the pipeline.
New Kinds of Undifferentiated Heavy Lifting
Sorting through complexity and integrating compliance regimes have become part of cloud’s heavy lift. It requires expertise to choose cloud services—among the myriad options—that best meet a particular use case. It requires expertise to predict how chosen services will interoperate. A recent survey by Fugue showed that, to make cloud deliver on business expectations, a significant number of tools and services are typically in use: 30.6 percent of respondents used 6 to 10, 15.8 percent used 11 to 15, and 6.8 percent used 15 or more. The same survey suggested that many stakeholders “don’t understand cloud complexity”—26.1 percent of respondents saying C-level executives don’t, 35.8 percent saying IT leadership doesn’t, and 20.3 percent saying developers don’t.
On the governance front, the issues are around businesses and contractors making certain that internal policies (usually structured around security and system reliability concerns) and regulatory demands (around NIST SP 800-53, HIPAA, ITAR, and other laws) are met, while still capitalizing on cloud’s potential for efficiency. It’s rare to see an operation doing both easily and well. Audit reports yielding configurations in violation of a particular policy or standard often require sorting through thousands of lines of code. And, infrastructure might already be provisioned when it’s found to be in violation of a standard. Or, a new feature’s release might be stalled as a slow, cumbersome compliance check process rolls forward.
A System That Makes Heavy Lifting Lighter
The point of Fugue is to address these new kinds of undifferentiated heavy lifting in the cloud with a single system. That system lets teams use an app’s infrastructure-as-code and policy-as-code abstractions in one place with full cloud visualization, lets them dig deep into resource details in the code when they want to, and enables fast and wide replication of cloud deployments that are in compliance upfront, as a routine function of the initial code compilation. Here’s an app’s complete, interactive cloud visualization with Fugue:
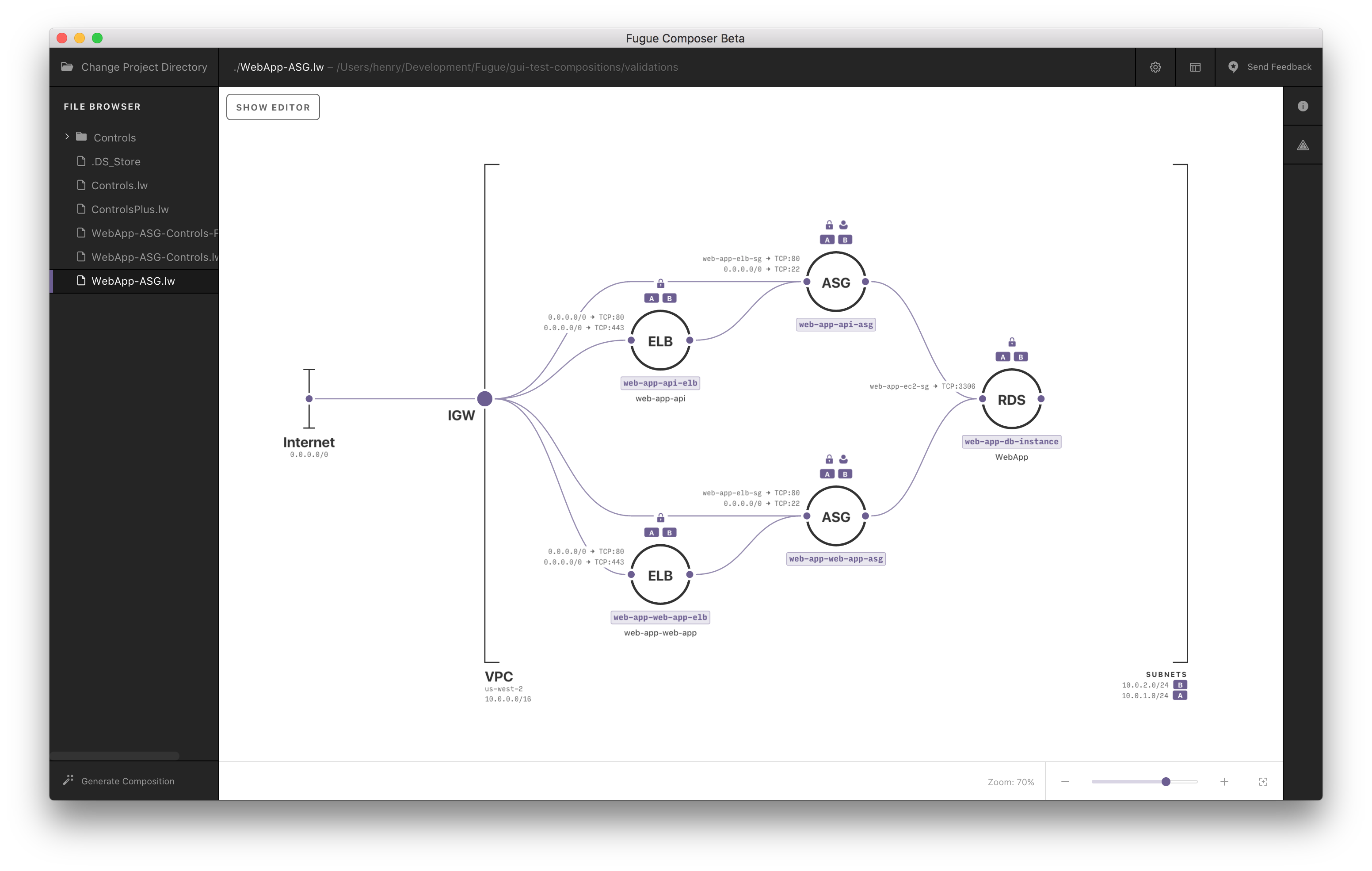
Reducing undifferentiated heavy lifting is baked into every part of the software. Even installation. The work that's automated in Fugue's installation is work that must be done to get up and running securely in the cloud, but shouldn't be complicated, manual action—as it is in other approaches—that pulls developers away from adding value to their company's applications. As one example of many that demonstrates Fugue’s streamlined approach, let’s look at installation in some depth.
One Command System Installation that Bootstraps Everything
Most ops solutions on the market—whether they’re billed as cloud management, cloud orchestration, cloud automation, and the like—require you to build out a whole other layer of preliminary infrastructure before you ever actually use the solution in a production-ready environment.
If you were to set up a well known container management system, for example, you have to own the care and feeding of work nodes, a master node, etcd (for production, a five or seven node cluster), monitoring, backups, and a plan for what happens when any of it goes down. With another common solution, before you really get started, you have to run a specialized server, make sure it’s highly available and it has a PostgreSQL database it talks to, which you need to set up and back up and manage. You have to make sure all of the preliminary layer is healthy not just during setup, but the next day, the next day, the next day, and so on. Yet another solution asks you to complete 19 steps—creating S3 buckets, a VPC, seven different security groups, load balancers, DNS records, an RDS subnet group, etc.—just to have a functioning layer to implement the solution.
With Fugue, on the other hand, you type fugue install, you hit enter, and you walk away for 15 minutes. When you return, everything needed has been automatically set up. Fugue’s Conductor (a powerful, async, controlling agent interfacing with cloud APIs) is running in an AutoScaling group. So if it goes down, it comes back up. The Conductor itself is completely stateless; all of its state is kept in DynamoDB and S3—so that’s a class of stuff you don’t have to worry about. All key management is handled automatically for you. That fugue install command automates Vars set up (Fugue’s replicated key/value store for coordination, configuration sharing, credential synchronization, etc.). Various queues and topics are automated as well.
Fugue’s footprint in your AWS account is a very fully featured orchestration system that has a lot of the same characteristics of other systems and some highly distinctive ones. But, unlike other systems, you don’t have to own bootstrapping and the continual care and feeding of all the required infrastructure. The one fugue install command literally bootstraps everything for you. Then, the Conductor takes care of its own infrastructure forever. You get this magic seed that you drop into your account and it unfurls a distributed system for you that you don’t have to worry about. Here’s how it renders on your CLI:
FugueWriter:fugue-book
$ fugue install[ fugue install ] Installing Fugue ConductorInstall Details:
Conductor AMI ID: ami-a1b2c3e4
AWS Account: FugueWriter/0xxxxxxxxxx9
Region: us-east-1[ WARN ] Would you like to proceed with installing? [y/N]:y
Installing the Fugue Conductor into AWS account FugueWriter/0xxxxxxxxxx9.
FugueAutoScalingGroup Working...
FugueCliResponsesDb Working...
FugueHealthCheckDb Working...
FugueIam Complete FugueIamInstaller Complete FugueIamUser Complete FugueInstanceProfile Working...
FugueInternetRoute Working...
FugueLaunchConfiguration Working...
FugueNotificationDriftTopic Complete
FugueNotificationKillTopic Complete
FugueNotificationResumeTopic Complete
FugueNotificationRunTopic Complete
FugueNotificationSuspendTopic Complete
FugueNotificationSystemTopic Complete
FugueNotificationUpdateTopic Complete
FugueResourceEventsTopic Complete
FugueRouteTable Working...
FugueSubnet1 Working...
FugueSubnet1RouteTableAssociation Working...
FugueSubnet2 Working...
FugueSubnet2RouteTableAssociation Working...
FugueVpc Complete
FugueVpcGateway Complete
FugueVpcGatewayAttachment Working...
FugueVpcSecurityGroup Working...
-----------------------------------------------
Overall Progress [############.............] 50%
[ HELP ]
Exiting the install command while in progress (CTRL+C) will only stop progress tracking and *not* the install itself.
With other systems, you’ll need at least a week or two to have resources at the point where you can sleep at night and feel like the system can manage everything and not go away. With Fugue, whether you’re trying it for the first time or rolling it out into production, it takes 15 minutes and one command to get to the same point. And, there’s no continual care and feeding of components. That’s reducing undifferentiated heavy lifting. That’s indicative of the way the entire system has been constructed to remove types of cloud complexity that don’t need to be there.
