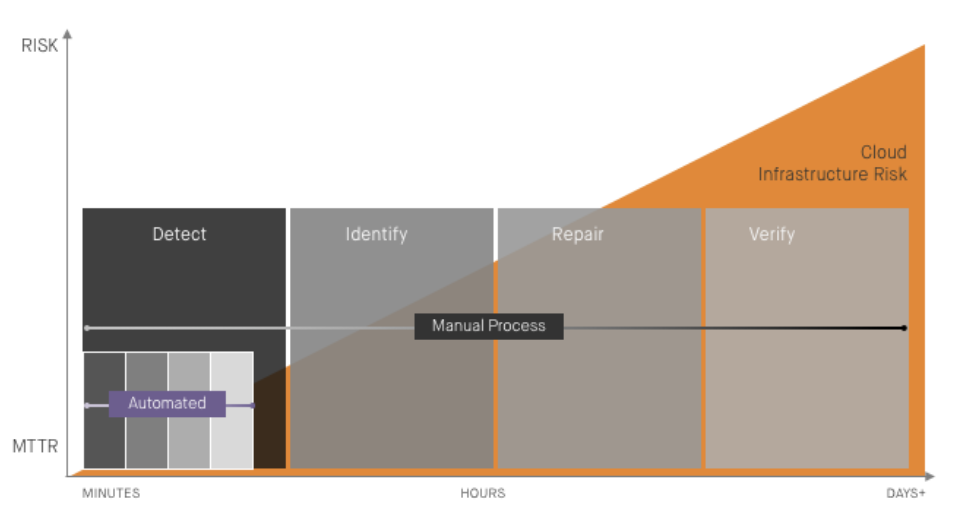
We’ve talked a lot about the risk of cloud misconfiguration and why it’s critically important to have a Mean Time to Remediation (MTTR) for cloud infrastructure misconfiguration that’s measured in minutes, not hours or days. But why are cloud misconfiguration MTTRs more often measured in hours or days? And how many man-hours are teams wasting in their attempts to manage this problem?
We work with a wide variety of enterprises using cloud at scale—from federal agencies to Fortune 500 companies to non-profits. What they all have in common is that cloud misconfiguration is not just a critical issue they all must contend with, but it’s a major management burden that soaks up significant time and expertise. Simply put, it’s a massive headache.
The scenario that follows is hypothetical. But cloud operations professionals will likely recognize it and identify with it (and perhaps wince a bit). The misconfiguration in this case is often referred to as a “configuration drift” event, as opposed to a misconfiguration provisioned via an approved deployment pipeline. Every cloud ops team operates differently, but this scenario captures the essence of what we’ve observed as commonplace.
10:00 AM - The Misconfiguration Begins
The day was proceeding just like any other for Jeremy, the junior engineer on Complicado Corporation’s DevOps team. Working remotely at his neighborhood Starbucks, Jeremy moved methodically through his queue of support requests. One request required server logs—in this case, from an Amazon Web Services (AWS) EC2 instance running an in-house database application. So Jeremy opened up the AWS Console and logged into the EC2 Dashboard. Being remote at a Starbucks, and not wanting to deal with the hassle of getting an IT ticket approved to allow SSH access, he decided to take it upon himself to modify the EC2 Security Group settings.
10:18 AM - A Monitoring and Alerting Tool Detects the Misconfiguration
Complicado’s DevOps team uses a common cloud infrastructure monitoring and alerting tool, which typically scans environments roughly every 15 minutes looking for configurations it suspects may be a problem. The tool noticies this misconfiguration and creates an alert.
11:20 AM - A Human Recognizes the Alert as Critical
Early in their cloud journey, the DevOps team had email notifications turned on for any infrastructure alert, but that didn’t last long. They’ve since scaled out their cloud ops, which resulted in a lot of alert noise. Due to the resulting alert fatigue in the SOC (Security Operations Center), they turned off email notifications and established a policy that someone needed to review the alerts once per hour.
Today, it’s Shireen’s turn to review alerts. She sees the alert for Jeremy’s action—the 16th alert in the queue—and recognizes that this misconfiguration is an exceptionally bad and unfortunately common one.
11:30 AM - A Human Validates the Misconfiguration
Shireen reviews the critically marked alert for accuracy and to confirm that it is not a false positive. She also checks to see if this misconfiguration generated other alerts for suspicious traffic, since having an EC2 Security Group opened to the world sometimes results in successful or attempted exploits. Was anything missed?
Shireen flags the misconfiguration for immediate remediation. It’s put in a queue for another team member to remediate.
1:15 PM - The Misconfiguration is Remediated
Amanda, a member of the Infrastructure Team, returns from lunch and receives Shireen’s remediation notification. She first confirms with the Security and Incident Response Team that she’s authorized to change the correct EC2 Security Group, which operates amid a virtual sea of other Security Groups. Now having authorization, Amanda manually logs into the AWS Console and corrects the configuration for the Security Group, opening up a second opportunity for a misconfiguration due to human error.
1:20 PM - The Remediation is Verified
Amanda verifies that the rule is now gone and forwards the CloudTrail logs to Shireen to include in a report later this afternoon.
3:30 - 5:00 PM - Producing Misconfiguration Reports
Shireen spends 1.5 hours compiling a report for every critical misconfiguration that was identified and remediated. The report answers the following questions for each:
- What resource was affected?
- What configuration was changed?
- Who was responsible for the misconfiguration?
- Did the misconfiguration violate regulatory compliance policies or internal security rules?
- What time did the misconfiguration occur?
- When was the misconfiguration identified and flagged as critical?
- When was the misconfiguration remediated and verified?
- Who remediated the misconfiguration?
- What steps are being taken to ensure such a misconfiguration never happens again?
The last is a big inside joke within Complicado’s DevOps teams because the answer is always “use a monitoring and alerting tool, manually review alerts, flag critical misconfigurations, and remediate them manually.”
Postmortem
Because it lacks security automation that detects and remediates any cloud infrastructure misconfiguration the moment it occurs, Complicado Corp wastes a lot of time reviewing alerts, flagging critical misconfigurations, manually remediating them, and producing daily compliance reports. Today, Shireen spent four hours managing alerts, and Amanda two hours remediating them. And until Complicado enforces compliance policies and sufficiently governs its interfaces to cloud APIs, folks like Jeremy will continue to create similar misconfigurations.
Jeremy’s misconfiguration exposure existed for three hours and fifteen minutes. That’s typical for the industry, but it’s too long for comfort. What no one at Complicado knows is that this misconfiguration was identified six times by bots that constantly scan cloud infrastructure looking for misconfigurations just like Jeremy’s to exploit. Did a security incident result? Perhaps not, but there’s no time to find out—another screenful of alerts awaits review...
