A lot of folks have realized that manually fixing cloud infrastructure to correct security and compliance issues is just too slow and error prone to handle the threat landscape on the cloud. An increasingly common approach to speeding up remediation these days is to use cloud functions, such as AWS Lambda or Azure Functions, connected to a threat detection tool, to remediate specific cloud misconfigurations.
But there is a better approach to the problem that’s more comprehensive, maintainable, and scalable: autonomous self-healing cloud infrastructure via baseline enforcement. In this post, we’ll first explore the method of using a collection of automation scripts to address misconfiguration, and then we’ll compare that to autonomous self-healing infrastructure.
The “bag of scripts” approach
The usual way this is implemented is that the DevSecOps team decides that they cannot tolerate particular misconfigurations in the cloud, and they start writing scripts to correct for particular issues in an automated way. These are usually connected to a first generation cloud security scanner that is detecting the issue, triggering the script.
For example, the security team might decide that having unencrypted AWS S3 buckets is always unacceptable. They then configure a scanner to look for unencrypted S3 buckets, and write a script in Python that takes in an S3 bucket ID, and deletes it or re-configures it. They then configure the scanner to call the script via a Lambda function when it detects this particular misconfiguration.
There are several major problems with this approach.
Unexpected Changes
The first is that the DevOps team is going to inevitably see some really mysterious behavior in their cloud environment. If they’re new to cloud, they are likely using a GUI console to build their infrastructure, but if they’re more mature on their cloud journey, they’re using infrastructure-as-code via tools like Terraform or CloudFormation. In either scenario, they’ve made a deployment, and part of it has disappeared or been modified, and they probably don’t know why, as the security scanner to Lambda script machine is outside their toolchain. This often yields an understandable adversity to automated remediation, as it can do unexpected things for the folks whose job it is to make sure the business is operating with reliability and efficiency. Put another way, there are two different systems that can come into conflict because there is no single source of both truth and trust.
Incomplete Policy Coverage
The second problem is that the collection of scripts will never be complete from a policy and security standpoint. Trying to predict everything that could possibly go wrong is impossible, and trying to write code for even the subset that is identified becomes a long-term commitment. There are code repos on GitHub that have hundreds or even thousands of remediation scripts for different scenarios. While this approach may seem expedient up front, in fact it’s a long-term investment in maintaining what will become a large codebase over time. Lines of code are ultimately liabilities, as maintaining software is more expensive than building it. And it will always remain incomplete, both because not every misconfiguration can be predicted, and because the CSPs are constantly adding new services that introduce additional threat surface.
Code Sprawl
The third problem arises when different applications have different security postures. It might be just fine for one application to have a particular port open on a security group, while it’s a major security hole for another one. You now have to either fork your scripts and have one for the first system and a different one for the second, multiplying the code accretion and maintenance problem, or agree broadly on what is acceptable or not in cloud, creating either increased attack surface or too much restriction for innovation to take place. All bad choices.
Lack of App Reliability Support
The fourth problem is really more about inadequacy than active harm. Cloud infrastructure often experiences configuration drift post-deployment, and the scan/script approach doesn’t offer any help with fixing things that get broken unless those breakages are specific security issues you are scanning for. In fact, it may act in conflict with other tools that are put in place to keep things working.
It turns out that by combining security enforcement with fixing things, both problems are easier to deal with.
Autonomous Self-Healing
This approach solves both the policy and security concerns and the configuration drift and system health issues nearly everyone has with cloud infrastructure at scale. Before getting into the details, we need to establish some concepts.
Known-Goodness
To use autonomous self-healing without harm, we first need to have a known good state to heal back to. This known good state needs to contain both the functional and security requirements of the system. For a cloud system to be “good” in this definition, it must both work as intended, and not contain any security flaws. This means we need to establish goodness during the development lifecycle - not after the fact.
At Fugue, we do this by providing you with detailed information on whether your application meets policy at any stage of the life cycle. For example, you can deploy to your development environment, point Fugue at that environment, and know where you are in and out of policy in minutes. Then the DevOps team knows right away what they need to either change to be within policy, or get a waiver for certain controls on a given system.
This known-good configuration can now make its way through stage/test, and then to production, with the same checks along the way to make sure things are still in a good state.
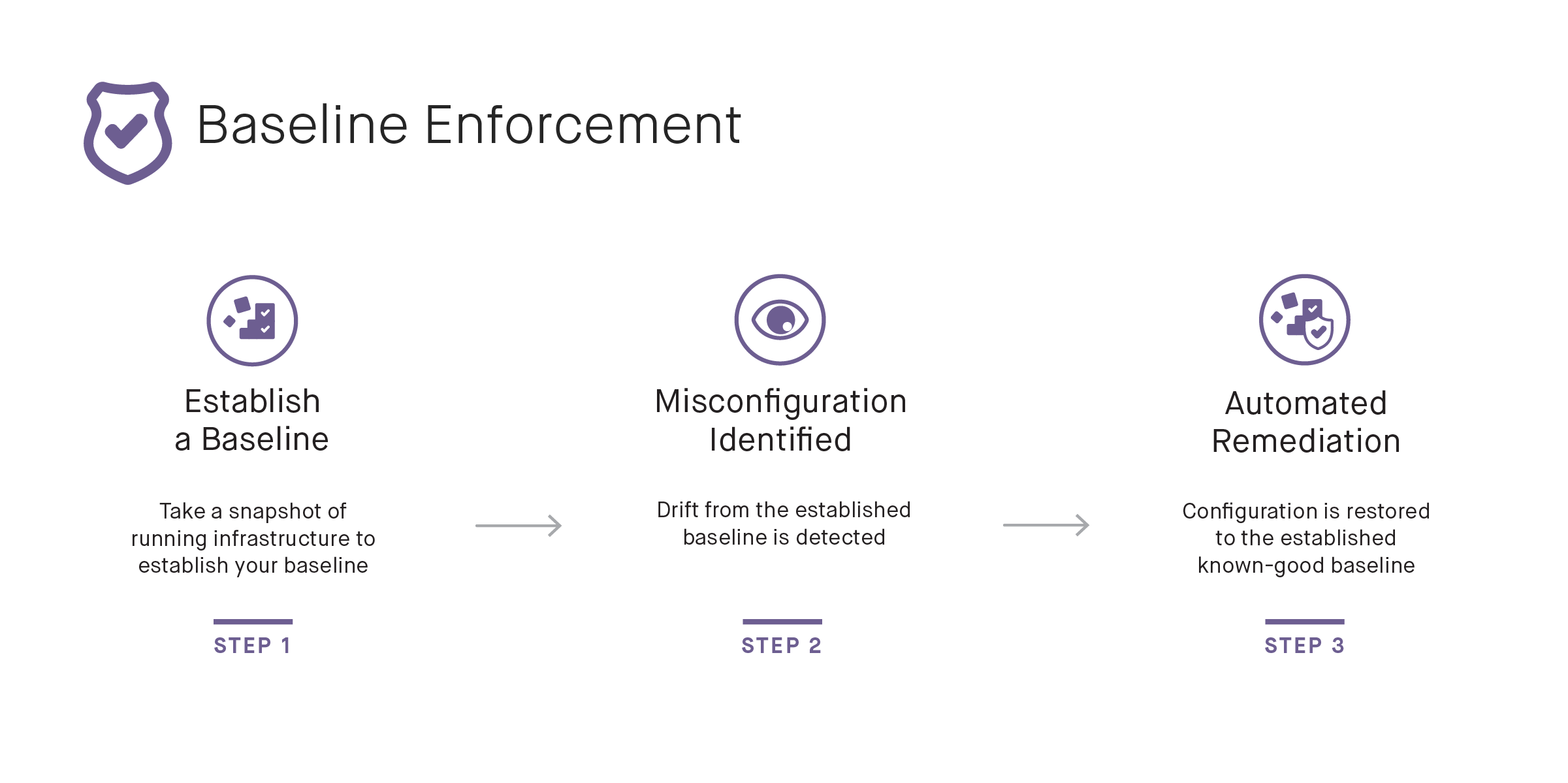
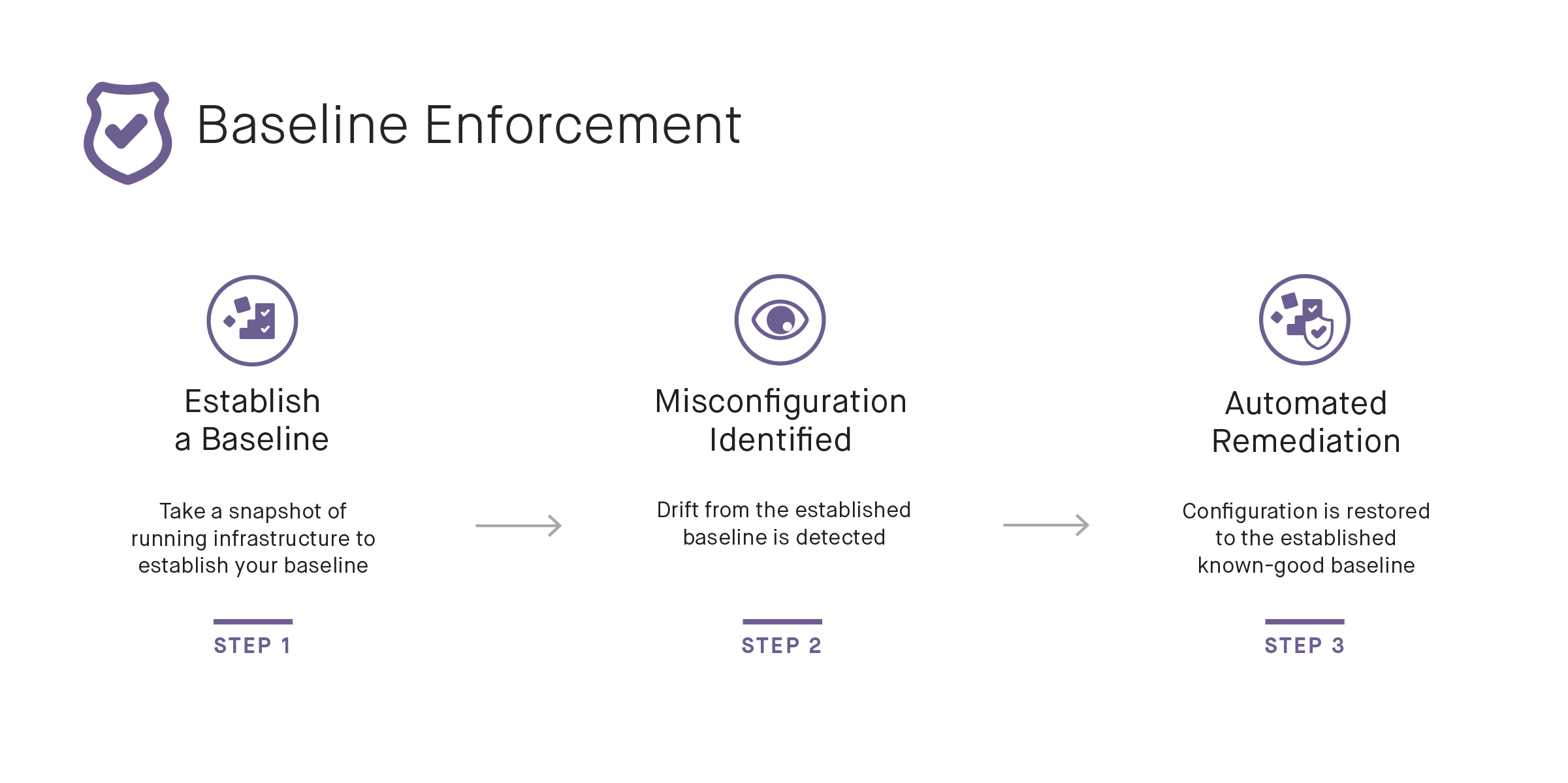
Baselining
Once a system is deployed in a known-good state, it can be baselined. This is a process where Fugue takes a snapshot of the state of the system, which has been approved by all stakeholders. When a system needs to be modified, a new baseline can be established.
Once Fugue has a baseline, we have everything we need to keep the infrastructure configuration both safe and healthy.
Drift Notification & Enforcement
With our known-good baseline, Fugue can now notify on any “drifts” to that configuration. Maybe someone had to do some manual maintenance on the system and left a port open, for example. Fugue is only going to report on actual drift, rather than create false positive issues, because the known-good baseline has been established. Put Fugue in enforcement mode, and your infrastructure becomes self-healing to the baseline.
Self-healing handles both security and health issues by autonomously reverting your configuration back to the last-approved baseline. There is no need to write remediation scripts or predict everything that could go wrong. If someone accidentally opens a dangerous port or broadens an IAM role, Fugue can autonomously revert it to the correct configuration. But if someone breaks something by closing a needed ingress rule, or even breaking a load balancer configuration, Fugue will reconfigure the resource to operate properly.
Note that this approach will never make guesses about what is correct, or create change or conflict in your organization between security, DevOps, and compliance, but rather puts everyone on the same team and provides information early and often.
And you don’t have to write and maintain bags of scripts.
View our webinar covering this topic here.
