This year, 2016, is a year of expansion. Below, you see an aggregate mapping of a wide swath of Earth’s cloud “hardware”—installed by Amazon Web Services, Microsoft Azure, Google Cloud Platform, and IBM/Softlayer. All of it, arguably, can be and eventually will be manipulated as parts of the same machine.
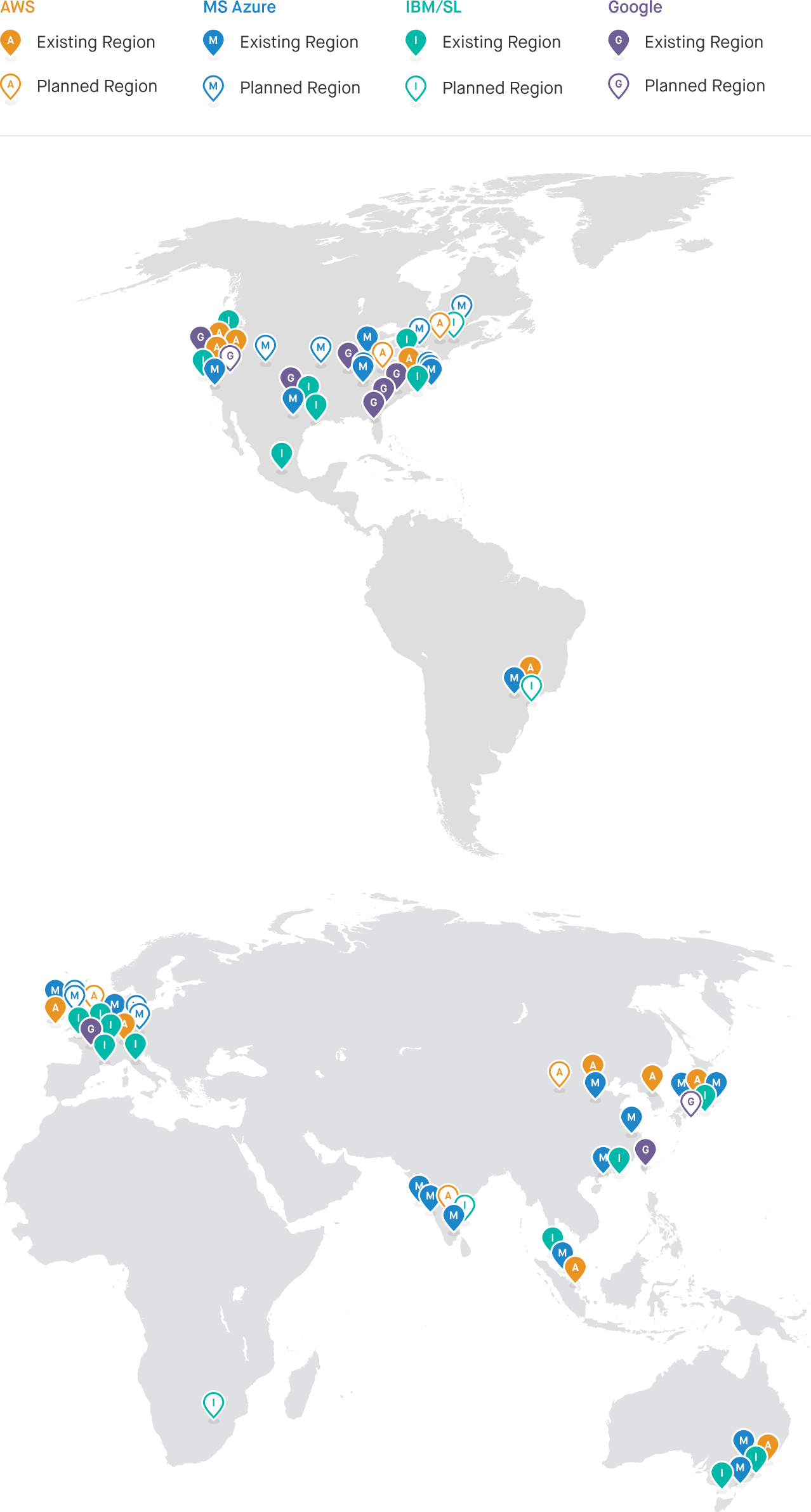
At the pinned locations are one or more large-to-colossal server farms or cloud data centers in marketing parlance. The available, raw facts about these physically secured, relatively non-descript constructions are noteworthy. We’ll look at some of what’s reported in a moment, but consider the chief players in this particular computing Weltanschauung, where the cloud is analogous in more than a poetic sense to a global machine. We’ve plotted four of them on the map: one that is breathtaking in capacity and the undisputed leader in current operations (AWS), another flexing muscle with bandwidth via its aggressive outlay of dark and lit fiber (Google), one surging with resources and more distinct geography covered than competitors (Azure), and one only now turning the corner into an embrace of genuine cloud principles but whose hardware outlay has promise (IBM).
Handy analogies aside, let’s get to the facts about recent and planned expansions in the cloud hardware outlay and questions raised by those expansions.
What's Reported
Azure publishes that it has more than 100 cloud data centers with about one million servers in 22 global regions around the world, with plans for 8 additional regions this year—two in Canada, two in Germany, two in the United States, and two in the United Kingdom. Regarding its aggressive region growth, Azure cites customer requirements and preference regarding data location. Indeed, low latency and nation-state compliance are priorities for most customers of any cloud provider.
AWS still doesn’t publicly specify its exact number of cloud data centers or servers in its 12 regions with their 33 Availability Zones, but back in November of 2014 a good server estimate was between 2.8 million - 5.64 million. A year and a half has passed and we know, according to AWS’s global infrastructure site, that this year will include at least 10 new Availability Zones in 5 new geographic regions: India, Montreal in Canada, Ningxia in China, Ohio in North America, and the United Kingdom. In January 2016, a lively read in The Atlantic reminded us that:
Unlike Google and Facebook, AWS doesn’t aggressively brand or call attention to their data centers. They absolutely don’t give tours, and their website offers only rough approximations of the locations of their data centers, which are divided into “regions.” Within a region lies at minimum two “availability zones” and within the availability zones there are a handful of data centers.
In AWS’s model, an AZ may be made up of more than one data center, but a data center does not typically include more than one AZ. Since things fail all the time and outage risk is rare but real, this makes good sense. AWS also claims denser storage servers than the densest available commercially, with a rack full weighing in at more than one ton. And, AWS builds its own electrical substations with power generation from 50 to 100 megawatts. No small potatoes—the rule of thumb with megawatts is that one can power about 1000 homes.
Google’s data center presence is more modest than that of AWS and Azure, but changes are on the horizon. Different Google cloud services are available via zonal, regional, and multi-regional coverage; its global physical data center locations have been fewer and farther between than Azure’s and AWS’s. (See our aggregate map for a rough idea.) But, two things are key. First, in March, Google announced two new regions opening later this year in Tokyo and Oregon respectively, with ten more beyond those opening through 2017. Wow. That marks a commitment to competitive expansion and aggressive investment. Second, Google’s core cloud “hardware” strength still arguably lies in an extensive network outlay constructed and owned by Google itself. Google laid its own fiber optic cable under the Pacific Ocean. It’s been deploying its own cable between its data centers for the past decade. Its networks are capable of Terabit speeds. Randy Bias, VP of Technology at EMC and Director at OpenStack observes:
Dark fiber doesn’t grow on trees. It’s incredibly costly to deploy and as what was in the ground has been sold off, it has become progressively more expensive. If you own the dark fiber and light it yourself, you can continue to push more bandwidth across the same strands by using new DWDM [dense wavelength division multiplexing] gear on either side. If you don’t have dark fiber, you only have access to “lit fiber” that limits how much traffic you can push across.
Perhaps not surprisingly then, a Google cloud user’s data transfer within a regional location and within a multi-region location is free. Data transfers within an AWS region and those to and from instances in the same AZ from a public or elastic IP address are generally not free. In fact, data across an AZ border (except to service endpoints) is frequently $0.01 per GB. That said, if past responses to competitor inroads are any indication, AWS is likely getting serious about owning its hardware in this arena. Finally, Google, also in contrast to AWS, hasn’t been shy lately in publicly sharing what their cloud hardware design and physical security look like—they even have a video.
And, Big Blue? IBM, it seems, has finally jumped into cloud authentically. The old model of selling IT infrastructure to enterprise in a professional services, high profit package is a dying giant. So, while BlueMix is, well, quite green, and its services and APIs are suffering their share of criticism, IBM nevertheless is picking and choosing from AWS, Azure, and Google’s models, embracing utility-style computing costs and easily scalable app deployment.
In our aggregate map the green pins representing IBM’s cloud regions include data centers that generally have less capacity than the big three, but IBM continues to construct locations internationally. IBM acquired SoftLayer, then expanded. It now operates about 19 regions with 46 cloud data centers across the globe, each with modest server capacity typically ranging from 8,000 to 15,000 units, though one Dallas location features 40,000+ server capacity. (By contrast, recall that in late 2014, it’s estimated that AWS’s data centers collectively held perhaps more than 5 million servers.) IBM expansions are happening in India, Brazil, Canada, and South Africa. The latter, announced on March 8, 2016, is especially interesting since it’s the first full cloud data center on the continent of Africa from one of the major global providers (i.e., AWS, Azure, Google, and IBM).
Another notable point-in-brief about all of these cloud hardware expansions involves sustainability. Efforts to construct an environmentally friendly footprint for cloud’s global computer appear to be underway. AWS convincingly markets the utility model itself as an energy saver, calculating an average 84% reduction in the amount of power required to run a typical on-premise data center for a given enterprise. Their solar and wind farms in US East and US Central “will be responsible for delivering more than 1.6 million MWh of additional renewable energy into the electric grids that supply current and future AWS Cloud data centers.” Google markets comparable data center burn efficiency as well as the repurposing and recycling of hundreds of thousands of servers. Microsoft notes that it “achieved Carbon Neutrality in 2014 and … that all new datacenters have an average 1.125 Power Usage Effectiveness (PUE), which is one-third less than the industry average data center PUE of 1.7.” And, IBM touts designing energy efficient data centers and “smart buildings” as well as using pollution forecasting to aid partners in China. When Italian designers get involved, the future—perhaps with data towers—looks even more interesting.
The Advantages of Distributed Cloud Hardware
This environmental sustainability of cloud computing hardware outlays compared with the typical energy waste from private, on-premise data centers is no small thing. In fact, in the end game, it may be the most important claim cloud advocates can make. But, at this point, it’s a by-product advantage and certainly smart marketing. Is it, right now, a driving raison d'être for cloud and its global hardware? Not really. So, what is?
Low Latency
Perhaps the most critical and oft cited advantage of globally distributed cloud hardware and a key reason the expansions are so aggressive is the low latency they make possible. Very low latency is possible within a region and even lower latency within an Availability Zone. Hosting applications in regions closest to user bases decreases customer-facing response times, enabled by technologies such as GeoDNS. Cloud providers’ networks are robust and latencies between the services themselves are low. The providers have extensive, redundant internet connections.
It’s this set of facts, this reality, combined with competitive pricing models, that makes cloud an attractive proposition to enterprises large and small. Enterprises with sprawling and varied international locations want low latency. More modest enterprises relegated to a particular region but with growth potential want low latency. Customer sensitivity about where data is located in order to decrease application response times and to speed application execution has become an expected cloud norm.
Compliance: Care and Feeding of Human Politics
Nations across the world have powerful laws and complex administrative regulations impacting data created, collected, and stored by private companies and public organizations. In the U.S., HIPAA, PCI DSS, SOX, Dodd-Frank, Can Spam, GLBA, CJIS Security Policy, and FISMA, et al., all impact the management of data.
Many other nations with vigorous interest in cloud, like Germany, Australia, and China, have requirements or provisions that impact multinational corporations, some with more controversial consequences than others. For example, while Chinese data privacy regulations are becoming more fine-tuned on the one hand, “sweeping State Secrecy laws permit national security to be used as a rationale for almost any measure pertaining to data privacy and the Internet/cloud.” In practical terms, Apple (and like-minded multinationals) can’t stand up to China’s government the way it can to the FBI via litigation, arbitration, political negotiation, and media engagement.
The EU, with respect to data residency (i.e., where cloud data is physically located) and data sovereignty (i.e., that data is subject to the laws of the country in which it is located), had established a quasi quid pro quo compliance model with the U.S. via the Safe Harbor Privacy framework. But, in October of 2015, the European Court of Justice invalidated the agreement. Then, on February 2nd of this year, the EU and U.S. moved fast to reach another agreement, the EU-US Privacy Shield—a political arrangement, not yet a full-fledged legal one. European data privacy advocates question whether the judicial redress provisions are futile in light of having no information about the NSA’s activities. Thus, data use remains controversial and subject to changing political will, effectively making cloud hardware expansion and strategies like tokenization a necessity.
With cloud hardware outlays multiplying across the globe, it’s easier for cloud providers to act in good faith with respect to compliance, while bringing the low costs and reliability of cloud to domestic businesses and global actors. And, contrary to some older arguments that still occasionally surface, the cloud providers featured in this post are generally better equipped than other businesses and organizations to do security and automation well. Their docs emphasize shared risk/responsibility models, but very thorough standards compliance and rigorous third-party auditing as well. They are judged on these imperatives constantly and it’s part of their core business. A learning curve nevertheless exists among enterprise users, especially those implementing hybrid deployment architecture. A recent survey (Feb 2016) found that “69% of respondents currently operating a private cloud, using public cloud services, or both say they are still learning how to apply security policies to hybrid cloud infrastructure.”
Fault Tolerance and Disaster Recovery
The major cloud providers offer entire manuals on fault tolerance and the implementation of disaster recovery for users’ systems because they’ve got a lot to offer. Redundancy is a central feature and advantage of geographically distributed cloud hardware. That redundancy means, among other things, extremely durable storage via cloud services like AWS’s S3, Google Cloud Storage (GCS) with its multi-region bucket support, and Locally Redundant Storage (LRS) / Geo Redundant Storage (GRS) from Azure.
A failed application can hinder, cripple, or even ruin a business, especially if failure is sustained or frequently repeated. Cloud providers and IT professionals expect failure but fundamentally seek to do two things better and more cost-effectively with cloud computing than with on-prem: (1) minimize “Mean Time To Repair/Recovery” (MTTR) and (2) maximize “Mean Time Between Failures” (MTBF). Consider the following:
- Multiple AZs within a single region minimize potential Mean Time To Recovery (MTTR).
- Multiple regions mean that there is little to no time required to provision new hardware in a new locale, again minimizing Mean Time To Recovery (MTTR).
- Data replication services between regions further reduce Mean Time To Recovery MTTR in the event of a failure.
- Cloud provided services, spread across AZs within a
- region, have high availability rates and consequently, very high Mean Time Between Failures (MTBF) for services.
What about cloud’s harshest critics who warn of the eventuality of large-scale disaster—of targeted terrorist/warfare/espionage attacks on cloud data centers—that would do more widespread damage in a few hits than is possible with the traditional build-your-own data center model? As with a power grid, the more geographically ubiquitous and redundant the physical equipment is, the more resistant the system becomes. Yet, if cloud ultimately represents “one box,” are we ultimately looking at an infected box? Of course. So what. Bombardment is the default state and multiple regenerative strategies at every unit of scale are the cloud’s inherent defense.
The Challenges of Architecting Globally
Capitalizing on the advantages of distributed cloud hardware hasn’t been easy for many businesses. Engineers and leadership face technical and nontechnical challenges. The latter can include finding real estate in close proximity to existing comm links, negotiating with foreign contractors, and navigating labor regulations, among many other things. Our focus here is technical. Let’s briefly look at a few obstacles.
Each App Is An Individual
Much about an application’s development and deployment depends on the particular app’s functionality, its intended audience, which services yield an optimized user experience, what the best architecting of those services might be, etc. There are infinite combinations of cloud services that can be utilized by a single application. To increase application performance, predictability, and reliability, all utilized cloud services should be local to the application. A developer needs more than a cursory understanding of the wide array of cloud services available to know what aligns best with a given app; there’s a level of decision-making and complexity in this that can snowball quickly. And, as cloud stands now, depending on the provider, some services are available in some regions and not in others.
Portability
Think about data gravity. Data's heavy, attracting applications and services to its location, accumulating a denser, more complex mass of dependent computing over time. Cloud providers know that big piles of data are slow and expensive to move. There’s a financial incentive for them to encourage customers to bring all their data, move in, and stay awhile. Once committed, customers often need to use other provider services against the data. That’s an additional challenge related to portability, "stickiness." There's an increasing number of sticky services in cloud provider offerings. Unique approaches to computation force developers to use applications that are tailored to those services. Lambda, EMR, Redshift, Kinesis, and even SWF are examples on AWS. Cloud providers end up blending IaaS and PaaS. How locked-in you are often depends on your willingness and capacity to cut great code.
Depending on size and use of data, a mitigation can be syncing data across regions or cloud providers. This may be cheaper or better than moving it, depending on the use case. Nevertheless, moving or co-hosting services between cloud providers requires significant engineering resources throughout the application lifecycle (Development->Release->Operations & Maintenance). This is further exacerbated if different hosted backend technologies are utilized, such as AWS DynamoDB versus Microsoft Table.
With these considerations in mind, imagine an elegant DSL interface and engine-of-automation that provide genuine portability, first inter-regionally within a cloud provider’s global network, then inter-provider within the multi-provider global cloud computer. That’s the portability Fugue aims to bring.
Confusing Costs?
Cost confusion regarding individual cloud services is one thing. And, it’s real. Comparing costs between cloud providers is a nightmare. A few companies are trying to benchmark and tackle this very problem, but the apples-to-oranges calculations are no small challenges to businesses that need to architect globally while reducing expenditures.
Stay tuned for more exploration of cloud hardware expansions, especially network expansions, and what that means for those migrating to cloud.
A special thanks to Josh Stella, Dom Zippilli, and Senior Software Engineer, Dan Kerrigan, who contributed thoughts to this piece and to Senior Designer, Michael Marcialis.

{kind=link}